使用Rebase操作抹去Git仓库中的敏感信息
2019年11月29日
使用Git的时候,有时候会碰到需要从Git仓库中永久“抹除”某些敏感信息的情况。例如不小心提交了密码之类的信息到仓库,此时只抹掉这些信息重新提交是没有用的,因为其他人仍然可以通过Git历史看到这些敏感信息。因此需要一种方法将这些信息彻底从仓库中抹去。
如果去网上搜索的话,能很容易找到使用branch-filter来处理的方法,例如
sh
git filter-branch --tree-filter "find . -name '*.*' -exec sed -i '' -e 's/OLDSTRING/NEWSTRING/g' {} \;" -fgit filter-branch --tree-filter "find . -name '*.*' -exec sed -i '' -e 's/OLDSTRING/NEWSTRING/g' {} \;" -f写法有很多种,但是思路都差不多,就是遍历一遍所有的提交,对这些提交执行指定的命令(例如用sed替换指定的内容,或者移除相关文件),然后重新生成新的提交和分支。
不过这种思路对于我来说却不太受用,原因有几个:
- 命令行掌握不太好,看到这种命令都不太认识,完全不敢直接放在项目中去跑
- 直接进行字符串级别的替换,在某些情况下不够用,例如想通过更复杂的编辑手段(新增文本、修改文本、删除文本同时操作)抹除敏感信息
- 直接对整个仓库/整个文件进行字符串级别的替换还是有些不放心,毕竟要修改的部分是明确的,却无法明确地指定这个命令只修改这一部分信息
那怎么办呢?其实在这种场景下,也可以尝试使用git rebase来解决问题。
rebase是干什么的
rebase顾名思义,就是重新确定一个提交(一个分支)的“基”,这个“基”就是指它的祖先元素。具体的做法是,首先将提交退回到“基”所在的点,然后将之前做过的提交在这个“基”的基础上重复做一遍。相当于修改了当前分支衍生出来的基础,因此中文也被译为“变基”。
还是举个例子:
新建一个仓库,然后做两次提交A1、A2:
sh
# 初始化
mkdir test
cd test
git init
# 两次提交
echo "A1">>1.txt
git add .
git commit -m A1
echo "A2">>2.txt
git add .
git commit -m A2# 初始化
mkdir test
cd test
git init
# 两次提交
echo "A1">>1.txt
git add .
git commit -m A1
echo "A2">>2.txt
git add .
git commit -m A2接下来分成两个分支,分别进行提交B1、B2和C1、C2:
sh
# 创建新分支
git checkout -b new
# 新分支提交B1 B2
echo "B1">>1.txt
git add .
git commit -m B1
echo "B2">>2.txt
git add .
git commit -m B2
# 切换主分支
git checkout master
# 主分支提交C1 C2
echo "C1">>1.txt
git add .
git commit -m C1
echo "C2">>2.txt
git add .
git commit -m C2# 创建新分支
git checkout -b new
# 新分支提交B1 B2
echo "B1">>1.txt
git add .
git commit -m B1
echo "B2">>2.txt
git add .
git commit -m B2
# 切换主分支
git checkout master
# 主分支提交C1 C2
echo "C1">>1.txt
git add .
git commit -m C1
echo "C2">>2.txt
git add .
git commit -m C2于是得到一张这样的分支图:
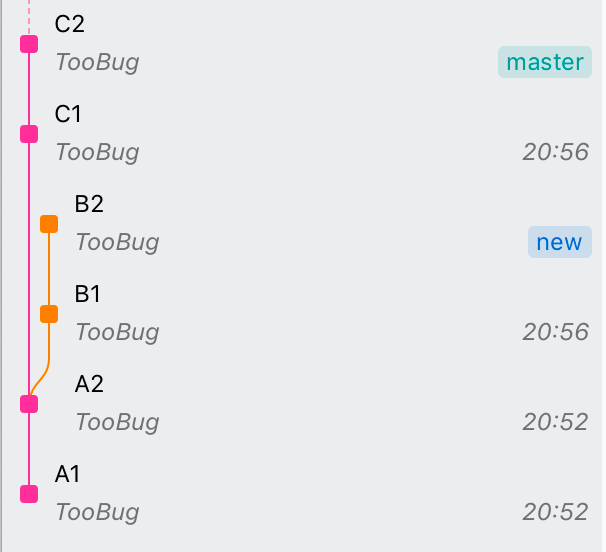
此时new和master两个分支分别指向B2和C2两次提交,而他们的共同祖先(即前文中说的“基”,这个说法不严谨,仅为理解),则是A2这次提交。此时我们就可以用rebase来改变其中某一个分支的走向。例如,让C1在B2的基础上修改,即让master分支的提交顺序变成A1-A2-B1-B2-C1-C2:
sh
# 对哪个分支rebase就切换到哪个分支
git checkout master
git rebase new# 对哪个分支rebase就切换到哪个分支
git checkout master
git rebase new而此时就出现了冲突,因为C1和B1两次提交都对1.txt做了修改。
sh
A1
<<<<<<< HEAD
B1
=======
C1
>>>>>>> C1A1
<<<<<<< HEAD
B1
=======
C1
>>>>>>> C1我们选择手工解决冲突,将B1放前面,C1放后面,解决完之后继续rebase
sh
# 用add标记解决完冲突
git add 1.txt
git rebase --continue# 用add标记解决完冲突
git add 1.txt
git rebase --continue此时分支图会变成这样,表明C1这次提交已经变基成功。但同时也能看到C2在变基的时候也产生了冲突。
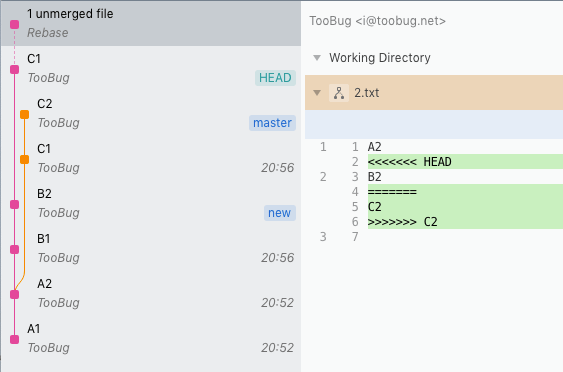
这里和上面一样处理即可。完成后就能看到变基后的分支图。

需要说明的是,尽管提交的描述信息(commit message)没变,但是C1、C2这两次提交实际上是新产生的,因此它们的commit id和之前的提交是完全不同的。
通过这个例子,能清楚地看到rebase命令的作用,即改变提交(分支)的基础。一般来说,在多人协作过程中,适合将同一分支互相拉取变更的操作使用rebase来完成,这样可以保持同一分支的提交历史是线性的,方便回溯。
使用rebase改变Git历史
在上面rebase的例子中,还有一个点值得注意,以C1这次提交为例,rebase前后两种情况下,虽然都是在1.txt结尾添加C1这行文字,但是基础和结果都是不同的。在rebase之前,1.txt的内容是由A1变成A1\nC1,而在rebase之后则是由A1\nB1变为A1\nB1\nC1。
可见在rebase的时候,不止是提交的父节点(“基”)会变,文件内容也有所变化。而我们之前在rebase时面临的冲突,也正是因为这个变化所带来的。但同时,正因为有这样一个变化,使得我们有机会通过rebase的方式来永久改写Git仓库中某一个文件的历史。
仍然看上面的例子,现在只看rebase之后的情况。在C1这次提交中,我们为文件1.txt在结尾处添加了内容C1。假设这个C1是一个很敏感的信息(例如密码),我们要如何将它从仓库历史中抹去呢?
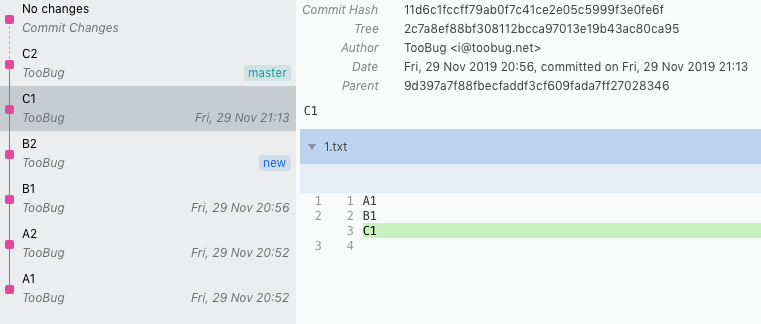
首先我们在C1提交之前找到一个点,例如B2,然后基于它新建一个分支。(例如new这个分支。)接下来在这个分支上,对文件1.txt进行修改,例如我们增加一行C2。即1.txt内容变为
A1
B1
C2A1
B1
C2并进行一次提交。
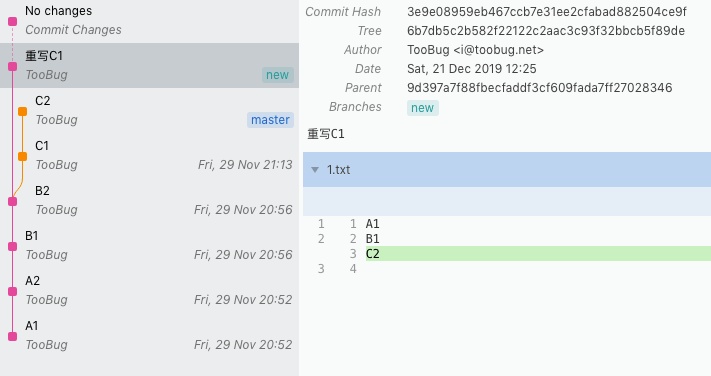
接下来,我们对C2这次提交(即master分支)进行rebase操作:
sh
> git checkout master
> git rebase new> git checkout master
> git rebase new此时git会告诉我们,产生了冲突。
First, rewinding head to replay your work on top of it...
Applying: C1
Using index info to reconstruct a base tree...
M 1.txt
Falling back to patching base and 3-way merge...
Auto-merging 1.txt
CONFLICT (content): Merge conflict in 1.txt
error: Failed to merge in the changes.
Patch failed at 0001 C1
hint: Use 'git am --show-current-patch' to see the failed patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".First, rewinding head to replay your work on top of it...
Applying: C1
Using index info to reconstruct a base tree...
M 1.txt
Falling back to patching base and 3-way merge...
Auto-merging 1.txt
CONFLICT (content): Merge conflict in 1.txt
error: Failed to merge in the changes.
Patch failed at 0001 C1
hint: Use 'git am --show-current-patch' to see the failed patch
Resolve all conflicts manually, mark them as resolved with
"git add/rm <conflicted_files>", then run "git rebase --continue".
You can instead skip this commit: run "git rebase --skip".
To abort and get back to the state before "git rebase", run "git rebase --abort".冲突内容正是原来的C1和我们刚在新分支上添加的C2:
A1
B1
<<<<<<< HEAD
C2
=======
C1
>>>>>>> C1A1
B1
<<<<<<< HEAD
C2
=======
C1
>>>>>>> C1前文假设,C1是我们要删除的敏感信息,因此此时手工解决冲突,将C1删除,留下C2。然后git rebase --continue即可。
可以看到我们的提交记录变成了这样:
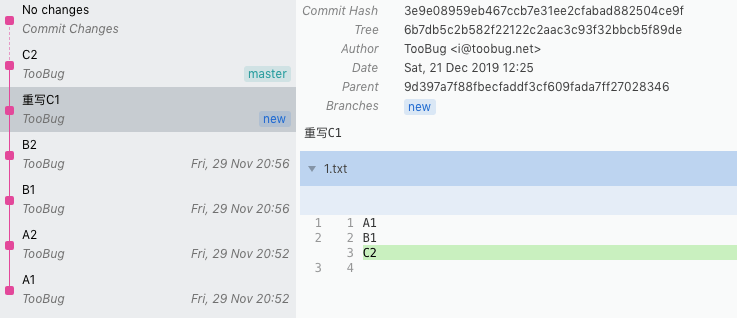
敏感信息被彻底删除了。
小结
上面只是展示了一种简单的情况,但已经足够说明使用rebase来删除代码库中敏感信息的核心思路和关键步骤了。
有一些值得注意的细节:
- 由于C1提交和重写C1的提交都只修改了一行代码,因此在
rebase过程中,把这一行的冲突解决完,并且git rebase --continue时,会提示没有变更(因为唯一的变更在冲突解决过程中被编辑好了),此时需要使用git rebase --skip跳过这次提交。 - 上面我们是使用
rebase操作时,编辑冲突的时机来编辑代码文件,从而将C1这个敏感信息删除的。如果无法保证一定产生冲突,则可以使用git rebase -i(交互式变基)来手工指定需要对哪些提交进行编辑,从而在不一定有冲突时,也有机会编辑代码文件,来将敏感信息删除。关于交互式变基,可参考网络上相关文档。 - 如果敏感信息在第一次提交就被带入版本库了,则上面说的“在C1提交之前找到一个点”无法完成。此时可以用
git checkout --orphan branch-name来创建一个完全空白且没有父节点的分支,并且将当前分支的提交基于这个新的空分支来进行rebase,从而获得编辑代码删除敏感信息的机会。
最后,一个提醒:不论用什么方法来修改版本库历史,都是在重写历史,虽然看起来提交的commit message是一样的,但是却是完全全新的提交和分支发展路径。当推送到代码库时,需要使用git push --force来强制推送,其他人则需要使用git pull --rebase来重写本地分支。