Skip to content 
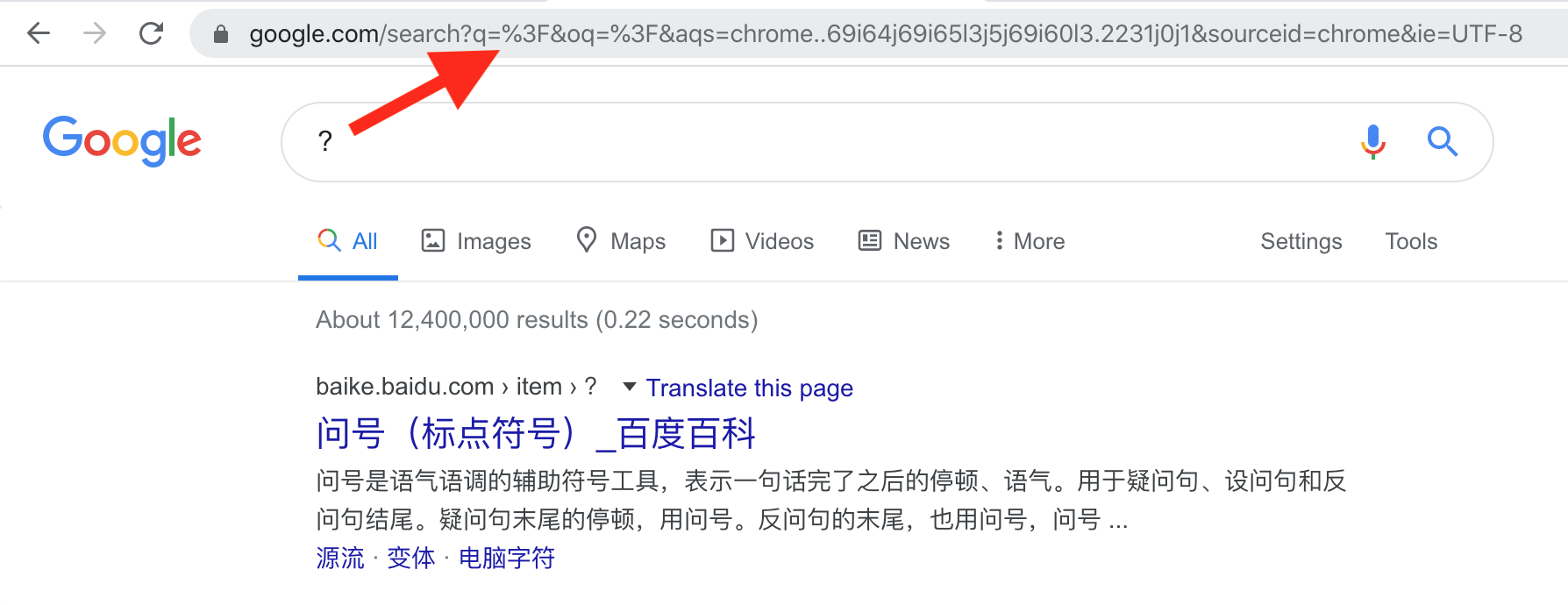

在pnpm中使用NPM镜像
2024年11月23日
在上一篇文章中,我为了解决网络阻断的问题,搭建了一个NPM代理服务器。文章发布后,收到了不少反馈,其中有一条是关于是否可以在pnpm中直接使用国内镜像。
首先明确一下问题背景与结论:
- 在使用NPM安装包的时候,如果遇到网络阻断问题,可以通过配置NPM镜像来下载依赖,但是有可能影响CI环境以及与他人的协作
- 在pnpm中,可以直接配置使用任意NPM镜像,而不会影响CI环境和他人协作
下面我们来详细看看来龙去脉。
NPM代理搭建指南
2024年11月16日
最近在家里开发项目的时候,时常碰到npm安装超时。想了一下手上有好多服务器,应该能解决这个问题,于是我搭建了一个代理服务器。
技术方案概述
npm registry有两个主要地址:
需要让npm客户端访问这两个域名的时候走自己的服务器,并突破封锁。
为博客添加Twitter卡片
2022年8月29日
写代码是一件与确定性为伍的事情
2020年9月19日
我们所处的世界充满了各种各样的不确定性。但有一件事是不存在不确定性的,即写代码。
多年以前,在我刚入行不久的时候,有一位前辈和我说过“出现问题的时候,先怀疑是自己的原因,因为机器是不会出错的,错的永远是人。”这句话我记了很久,也时不时就会翻出来回想一番,也会冒出很多更细的想法:那机器不也是人造的?机器的程序不也是人写的?就一定是自己的原因,不能是别人的原因吗?但反复想了很多年,还是觉得这句话相当有道理,即使是别人的原因,那错的也是人而不是机器。
这其实就是写代码时的确定性,我们写的代码会被怎么运行,是非常确定的。即便它要依赖更多的底层软硬件机制,但仍然是确定的,只是找出这个确定性的过程更加复杂而已。
一个例子
如果你看不懂例子,跳过就好。
背景
项目中需要上传下载文件,使用的是某云服务的存储服务。在下载的部分,为了方便,使用Node.js封装了一个下载方法,返回一个Stream,而这个Stream本质上是由http请求库request.js请求后返回的。最后由koa框架返回这个Stream给浏览器。
请求下载 -> 下载方法 -> request.js请求云服务 -> 返回Stream
代码大致如下:
javascript
router.get('/api/download-file', async (ctx) => {
ctx.body = Download.getPrivateStream(ctx.query.fileId);
});router.get('/api/download-file', async (ctx) => {
ctx.body = Download.getPrivateStream(ctx.query.fileId);
});然而,同样的代码,在不同的项目下,表现却大不一样,A项目访问图片时是直接在浏览器中显示图片,B项目访问同样的图片却变成了下载。调试工具一查看,发现它们有不一样的HTTP Header返回:
- A项目
Content-Type: image/png - B项目
Content-Type: application/octet-stream
Urlencode踩坑日记
2020年3月31日
【问答】为什么前端越来越复杂?Node.js有什么作用?
2020年3月18日
本文来自知乎问题:为什么要把前端搞的这么复杂,UI 组件不是很好用吗, 难道就是为了推广 nodejs 和 npm 吗?
这个题目中有无数槽点:
画个界面只要快就好了吗?JS类库能帮你解决渲染慢的问题?类库和组件能帮你解决所有的兼容问题?不需要高并发所以就不需要架构?
这里的每一条都值得展开来反驳,但鉴于题主的主要疑问不在这里,就不跑题。
这个问题的核心,抽取一下就是两个:
- 为什么前端越来越复杂了
- Node.js在前端开发中是干什么的
Sequelize的一些小技巧
2019年11月10日
Sequelize.js是一个用于Node.js的数据库ORM库,支持Postgres、MySQL/MariaDB、SQLite、SQL Server等引擎。
本文记录一些团队在使用Sequelize过程中积累的经验教训。
介绍
ORM即Object Relational Mapping,中文叫“对象关系映射”。简单地说就是可以将数据库的各种对象(表、字段)及关系映射为程序语言的对象和关系,从而使开发者不需要直接操作数据库,转而操作对象即可。
例如,将表user映射为模型User后,从数据库中查询id为1的用户就可以直接调用findOne()方法:
javascript
const user = await User.findOne({
where: {
id: 1
}
});const user = await User.findOne({
where: {
id: 1
}
});这样做会带来几个明显的好处:
- 降低开发难度:ORM都有完善的文档,几乎所有的操作只需要按文档调用指定方法即可,不需要自己拼接SQL
- 提升安全性:ORM会处理好SQL注入问题,不需要开发者关注
- 降低封装复杂度:公共逻辑可以基于ORM封装,非常方便
下文不区分“模型”和“Model”,均指Sequelize中与数据表对应的数据模型。
【问答】为什么会允许babel这种解析工具的存在?
2019年3月28日
本文来自知乎问题为什么会允许babel这种解析工具的存在?
希望提问者真的没有在调侃……因为在我看来,这有点像“何不食肉糜”的提问了。
ES6又名ES2015,也就是在2015年定稿的,在定稿之前其实大家已经讨论了很久了。但是光讨论有什么用呢?没有任何一个环境是支持ES6运行的。所以就讨论讨论再讨论,然后大家一拍桌子,好,定稿?
事实上在ES2015之前,ES5可能就是这么定下来的,ES4可能也是这么废弃的。
这时候,就有个神奇的东西,叫6to5出现了,它的第一次提交出现在2012年9月。Initial import · babel/babel@aedcd4e 它的作用就是把ES6的代码编译成ES5的代码,它的神奇之处就在于,虽然一个能支持ES6的环境都没有,但是我们仍然可以使用ES6来编写代码。这是一种前所未有的模式,甚至在其它语言中都没有出现过这种模式。(希望不是孤陋寡闻,至少py3 -> py2是没有见到类似工具的。)
于是,我们可以在规范还没有定稿的时候就先用用看,用着觉得不爽了再回去修改规范。这样是不是比拍桌子要科学得多?事实上现在的ES规范制定过程就是这么干的,定了stage 0到stage 4等几个级别,而且规定了需要在多少个环境中先验证,验证完之后才可以定稿发布。基本上可以毫不客气地说,这个东东就是由6to5开创的新局面。
如何与NPM package-lock.json愉快地玩耍
2018年7月26日
背景
对的,最近写文章都会交代一下背景。因为按标题的套路,这本应该是一篇教程类的文章,但这种文章其实挺无趣的。之所以想写这篇,是因为确实碰到了一些很麻烦的事情。闲言少叙,我们进入正题。
最近我们前端代码打包正在接入Gitlab CI,使用Docker来作为Executor,也就是在Docker中进行前端代码打包,然后收集打包结果,以备发布时使用。打包时Docker镜像很自然地就选择了官方Node镜像,最新版本(Node 10)。
一开始我们尝试性地接入了几个项目,有使用NPM scripts进行打包的,也有使用Gulp进行打包的,一切都很正常。但是昨天在接入一个新项目,使用Gulp打包的时候,却突然碰到了报错:
sh
$ gulp gitlab-ci
gulp[85]: ../src/node_contextify.cc:631:static void node::contextify::ContextifyScript::New(const v8::FunctionCallbackInfo<v8::Value>&): Assertion `args[1]->IsString()' failed.
Aborted
ERROR: Job failed: exit code 134$ gulp gitlab-ci
gulp[85]: ../src/node_contextify.cc:631:static void node::contextify::ContextifyScript::New(const v8::FunctionCallbackInfo<v8::Value>&): Assertion `args[1]->IsString()' failed.
Aborted
ERROR: Job failed: exit code 134看了一眼这个错误信息,一下子就发现,这并不是来自JS层的错误,而是来自Node原生层,这就超出了我的理解范围了。
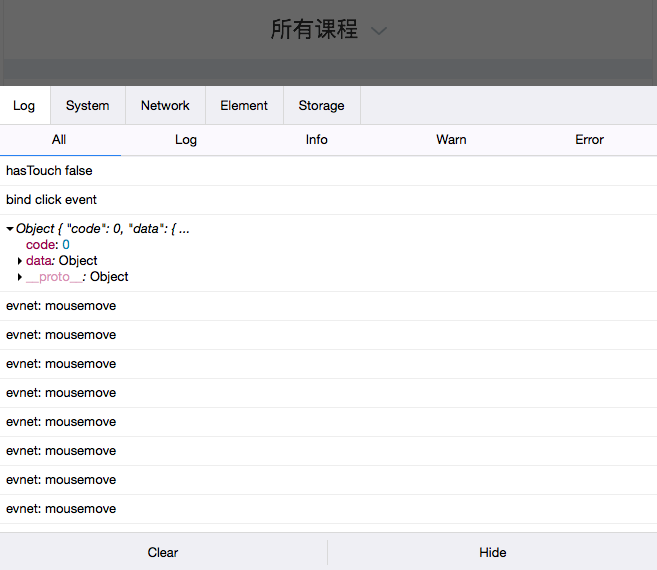
记一次企业微信webview bug排查
2018年7月24日
【问答】2018年的前端是否有『架构』可言?
2018年5月28日
Nginx + Koa 开启http/2 server push
2018年5月15日